
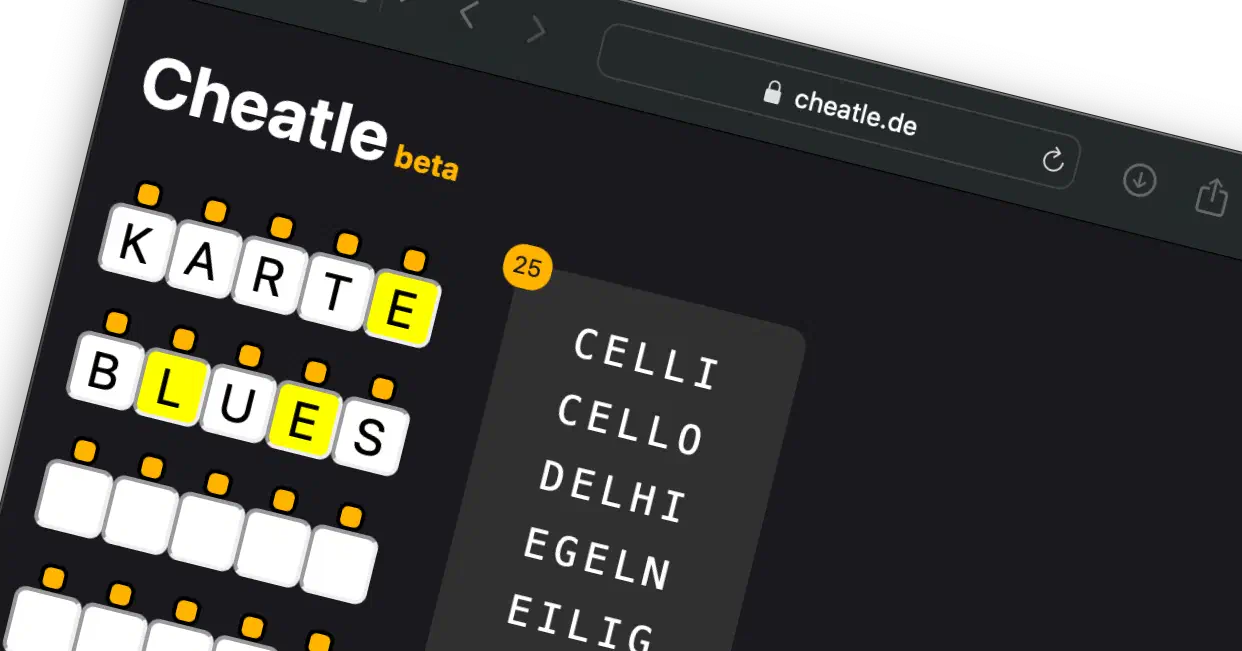
Ein Cheatle für Wordle!
Alle spielen anscheinend das Wortspiel Wordle bei der New York Times. Inzwischen gibt es das auch in der Deutsch/Österreichischen Variante wordle.at. Da juckt es einen ITler doch in den Fingern, dem müden Hirn etwas nachzuhelfen, wenn es klemmt.
tl;dr: Das Ergebnis ist hier: Cheatle.
Der wunderbare Erklärbär-Channel von 3Blue1Brown hat bereits ein schönes Video erstellt, das die Gelegenheit gleich nutzt, um mit Wordle Grundlagen der Informationstheorie zu vermitteln:
Das alles bezog sich allerdings natürlich alles auf die englische Variante.
Ich konnte mich noch dumpf erinnern, dass es früher bei FreeBSD (ich glaube sogar im Base-System) eine englische Wortliste gab, zu der man ein deutsches Pendant aus den Ports nachinstallieren konnte. Nur leider finde ich sie nicht mehr, kann sich noch jemand erinnern wo es die gab? Zum Glück fand sich dann schnell eine andere freie Wortliste im Netz.
Nachdem ich mir ein paarmal mit wüsten egrep Ausdrücken Nachhilfe beim Worldlen geholt hatte, wurde mir das schnell zu blöd und eine einfache App ist ja schnell gebaut…
Mit ca. 30MB ist die Liste allerdings viel zu groß für eine Webanwendung, zum Glück benötigen wir ja ohnehin nur Teile davon. Auf der Kommandozeile ist schnell eine passende Variante erzeugt, die Umlaute müssen ja noch gerichtet werden, auch die Groß-/Kleinschreibung ist für diese Aufgabe eher hinderlich:
cat wordlist-german.txt \
| tr '[:lower:]' '[:upper:]' \
| sed 's/Ä/AE/g;s/Ö/OE/g;s/Ü/UE/g;s/ß/SS/g' \
| egrep '^.{5}$'
> wordlist-german5.txt
Jetzt bleiben nur noch 37 kB übrig, mit der Browser-typischen (aber antiquarischen) gzip-Kompression sind das 16 kB über die Leitung, das scheint mir vertretbar. Mit dieser Wortliste kann man jetzt prima eine kleine Angular-Applikation bestücken. Praktischerweise ist für den schnell gefundenen Namen “Cheatle” auch gleich die .de Domain frei: cheatle.de. Für einen schnellen Schuss aus der Hüfte funktioniert das schon relativ gut. Was mir noch fehlt, ist:
- Eine Möglichkeit, die Liste auf diejenigen Wörter zu limitieren, die auch den maximalen Erkenntnisgewinn bringen, also keine unbekannten Buchstaben doppelt nutzen (oder vielleicht auch die Ergebnisse nach dem Informationsgewinn zu ranken?)
- Das Layout noch mobil vernünftig nutzbar machen, da habe ich noch geschlampt.
- Den maximal ineffizienten Suchalgorithmus (der eigentlich nur ein paar RegExps zusammenschraubt) durch etwas Effizienteres ersetzen (andererseits: Wozu?)
- Etwas Zeit, den Code so weit aufzuräumen, dass ich ihn auf GitHub schieben kann…
Schreib den ersten Kommentar: